



This article is a guest contribution by Ysengrin. It is a repost (with permission) from his personal blog. The original article can be found here: https://netrunnerscribbler.wordpress.com/2021/02/17/single-sided-swiss-how-it-works/
Intro
I have created a free application for tournament organizers to run single sided swiss events called the Side Aware Swiss System (SASS) and this article will describe how it pairs. I’m going to cover it first in a hopefully universally understandable way, and then go into a bit more depth of the actual math used for those interested.
Why Single Sided Swiss?
The very short summary of why I’m looking at single sided swiss for Netrunner tournaments is because the current format, double sided swiss (i.e. a match is two games, one on each side), has some problems.
- The structure makes 241s, (“two for one”) where instead of playing both games, the two players agree the winner of the first game gets both wins, very commonly the optimal choice for both players. This occurs when both players would need to get 2 wins to make the cut. But even beyond that, it’s often a higher expected value for a player to 241 every round.
- Intentional draws (IDs) are also extremely common. Because both players get a full win recorded, the top score bracket in most tournaments can usually safely ID into the cut playing very few games of Netrunner (this is further exacerbated with byes).
- Those two factors combine to mean early performances in Netrunner tournaments, against the weakest opponents (theoretically) end up having a significant impact on who makes it into the cut and who misses it.
- For new players, to Netrunner or just to a local scene, the etiquette of when you ID/241 can also be intimidating, and adds an extra burden to Netrunner tournaments.
- Finally, because 241’s side selections are not tracked, someone could theoretically 241 every round and just get one of their two decks the whole day.
Single sided swiss (SSS) reduces or eliminates (in theory) all of those problems. In single sided swiss, you are assigned your opponent as well as the deck you will play, and you only play that single game.
- 241s are eliminated entirely
- Intentional draws are much less common, and generally only good for the very best performers at the end of the tournament. This is because a tie is worth ⅓ of a match win instead of ½ of a match win in DSS
- This forces good players to play a much larger portion of their games, and removes the ability to game the tournament structure
However SSS does introduce three new potential problems.
- Playing the same number of games takes longer
- You cannot guarantee everyone plays their decks the same number of times
- There are more mismatched record pairings (this is somewhat dependant on how you count, as you could argue that every double sided swiss has a mismatched pairing)
The first issue is a challenging one, and I think a really important one to address, with potential solutions being cutting games (see this article for why I don’t think that hurts overall rankings) or reducing the amount of time a round is allotted. This is a tricky issue, as cutting games from a tournament to make the top cut more fair is primarily catering to strong players (though SSS gets people paired with closer ranked players faster). If that change comes at the expense of games for everyone, we as a community have to weigh that cost carefully.
This article is going to focus on the second potential issue, and how, with some math, we can actually handle it pretty well without making the third issue worse.
Algorithm in English
For my algorithm I wanted to make pairings based on two factors: the player’s wins (sometimes referred to as score or prestige) and the amount of times they’ve played each deck. I call this bias. So if a person has played their Corp twice, and Runner once I would say they have a Corp bias of 1 (the reverse would be a runner bias of 1). If they had played Corp 3 times and Runner 1 time, they would have a Corp bias of 2.
Traditionally, swiss systems that don’t care about side balance do some variation of solving a “graph” problem. Here graph stands for a collection of nodes (representing players) and the lines (called edges) that connect them (sorta like a spiderweb). For every player we draw a line connecting them to every other player. Each node represents a player, and each edge gets assigned a number representing the desirability of that pairing. Then the tournament organizer uses some algorithm to divide those players to create a “best” pairing.
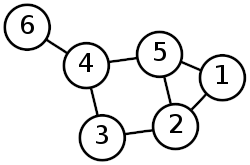
We use these edges to calculate how “desirable” a given pairing would be by assigning costs to potential pairings. Two players who “should” be paired against each other would have a small cost, and two players who you don’t want paired have a high cost. For the rest of the discussion I’m going to refer to the nodes as players, and the edges as the “cost to pair” a set of two players.
So for my algorithm, I followed the same strategy. In most swiss systems the cost to pair considers two things: what is the difference in tournament score, and have they played already. So the “equation” to figure out the cost to pair is simply:
Cost = Score Difference + Have They Played(if yes make this very big)
So when I went to make my algorithm I wanted to change as little as possible. My equation just adds one more cost which accounts for their side bias, which I call the Relative Side Bias. If both players have a Corp bias of 1, that increases the cost, if they both have a Corp bias of 2 that increases it even more. But if one player has a corp bias of 1, and the other player has a runner bias of 1 (or an even amount with both) the Relative Side Bias cost is 0. So the equation becomes:
Cost = Score Difference + Relative Side Bias + Have They Played(if yes make this very big)
There are lots of ways you fiddle with the exact calculations of score difference and relative side bias, but the most important thing is their relative size. If Score Difference has a larger effect on Cost than Relative Side Bias, then you’re more likely to end up with some players playing uneven sides. In the reverse you’re more likely to get pair up/downs, but fewer people play their decks an uneven number of times. In SASS, I have a term called the Score Factor which tweaks the relative sizes of the two terms so the TO can adjust how far the algorithm will look to find someone to balance the sides.
Example Round from Throwback Tournament
Standings after round 3 is concluded are pictured below. The Side column is counting the difference in Corp games played minus Runner games played. So a Side value of 1 means they’ve played 2 corp games and 1 runner game. And a side value of -1 is the reverse. (Because of byes three players have played only 2 games, one on each side)
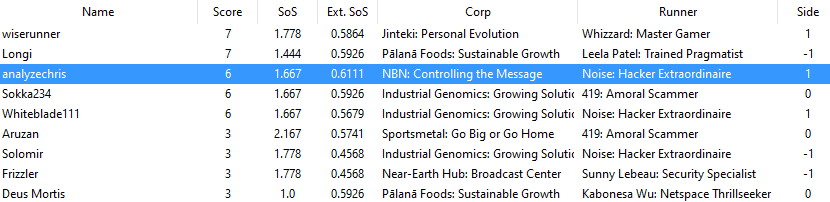
Going into round 4 we need to come up with a pairing for these 9 players. So let’s go through a basic idea of what the algorithm did, looking at how it calculated costs for analyzechris. To put numbers on the page I’m going to have the score difference term just be the differences between the two player’s scores (it’s slightly more complex in the actual implementation), so analyzechris vs Aruzan would have a score difference term of 3 (6 points – 3 points). And then, to match the math behind my algorithm, the side bias cost for pairing two players with the same side bias (i.e. both players have played more Corp than Runner) would be 10. So the whole table for analyzechris looks like:
Analyzechris:
| Opponent | Score Difference Cost | Side Bias Cost | Total |
| wiserunner | 1 | 10 | 11 |
| Longi | 1 | 0 | 1 |
| Sokka234 | 0 | 0 | 0 |
| Whiteblade111 | 0 | 10 | 1010 (they’ve already played twice) |
| Aruzan | 3 | 0 | 3 |
| Solomir | 3 | 0 | 3 |
| Frizzler | 3 | 0 | 3 |
| Deus Mortis | 3 | 0 | 3 |
So the best pairings for analyzechris would be Sokka234, Longi, and then any of the people with 1 win. In the actual tournament, analyzechris was paired with Deus Mortis. Why?
Basically because the algorithm looks to minimize cost across all players. In this case, there were an even number of people with the top score, and an odd number of people below, instead of having the top two pair down, they played each other, Whiteblade111 and Sokka234 got paired (at random), so analyzechris got the pair-down. Chris could have been paired against any of them, and so randomly got Deus Mortis chosen from the pool of players with 1 less win, and an opposite side bias.
Technical Details
Here I’m going to discuss some of the actual math and implementation things. This is not essential for most people, but for those that want to check my math, I figured it makes sense to write some things out more clearly.
I’m going to break out each of the three terms in a bit more detail as there are complexities to how each is calculated. My actual cost calculation looks like this:
Cost =1000- Score Cost * Score Factor – Side Bias Cost
I’m doing subtraction because the python library I’m using has a maximum weight function (not a minimum weight one), but all the math ends up being the same, so I’ll continue to use positive costs through the rest of the discussion. For those interested I’m using the python library networkx and its max_weight_matching function with maxcardinality=True to optimize the graph I build with the above cost function.
Side Selection
My implementation is a bit idiosyncratic, so sides are currently assigned near the end of the algorithm. There are a bunch of other ways you could implement this algorithm that handle side assignment and pairing differently (like making the graph directed instead of non-directed). But due to me trying to use the tools I had on hand, I take a somewhat unusual approach. First I make my graph (details below), then go through every pair and assign sides using a simple logic tree.
- If your opponent is the Bye, you get no side assigned
- If you’ve played this opponent before, you are assigned the opposite side
- If you and your opponent have the same bias, flip a coin
- If your bias is greater than the opponent (i.e. you’ve played more corp games) you run, otherwise you Corp.
Then when I check to see if every player if any of the following are true
- If they’ve already played the opponent twice
- If they’re against the bye and already received the bye
- If they’re having a rematch and the side they’re assigned would make their overall side bias worse ( abs(current side bias + assigned side) > abs(current side bias) and current side bias != 0)
If any of those three things are true, the edge weight is set to 1000, and I re-run the algorithm to optimize the graph with that edge essentially removed. This set of calculations is totally something that could be done upfront, and incorporated into the graph initially instead of post-hoc. When I was trying to solve a different problem related to my simulations running slow I tried to make my implementation vectorizable to reduce function calls, and I wasn’t sure how to make the above checks vectorizable. This ended up not saving me any computational resources, so was a bit moot, but I’d built up enough infrastructure that I decided to keep pushing ahead with it.
With an understanding of how I’m assigning sides, I think it makes sense to look at how the algorithm determines the weights for all the allowed cases.
Score Differences
The formula I showed above was just Player A score minus Player B score. And that’s what all of my testing did, and what I believe Cobr.ai does. However when running a simulated tournament, I got a weird pairing that made me want to modify that equation a little. What happened was there was one player with a score of 9, then there were an even number of people at 6, and an odd number at 3. So because pairing one person down 2 levels had the same overall cost as 2 people down 1 level, one of the minimal mappings (and the one the algorithm chose) paired the 1st player with the 6th player instead of anyone else in the top 5. So I needed some non-linear cost to make it so that two pairs being paired up/down 1 was preferred over 1 pair being paired up down twice. I ended up selecting triangular numbers, so the cost equation becomes (with the score difference being the difference of their scores divided by the points/win):
Cost = SD*(SD+1)2
So if two players has a score difference of 1 (i.e. one player has won one more game than the other) the cost of pairing them is 1*2/2 = 1. If the score difference is 2 the cost is 2*3/2 = 3, and SD of 3 has a cost of 6 (3*4/2). So each further level down has a higher and higher cost. I chose triangular numbers because they’re simple to calculate, and while they do grow faster than linear, they grow slower than my side bias calculation, which is below.
Side Bias Calculation
I adapted this side bias calculation from a paper by Olafson. For this one I’m going to start with the equation, and work backwards (for players A and B)
Cost =(Abias*Bbias >0)*8min(|Abias|,| Bbias|)
This is a lot messier. So let’s start with the left hand side. Abias and Bbias are signed quantities. So if Abias * Bbias > 0 that means either both are positive, or both are negative. So the left term is only true (which in Python is equivalent to 1) if both players have the same bias. If they have opposite biases, or one player has no bias, the value is zero and we’re done with the side bias calculation.
Onto the second term 8 raised to the power of minimum of the absolute values of Abias and Bbias. A lot of whys here. Let’s start in and work out. We chose the minimum of the biases because in the case where someone has a bias, we want to find the opponent with the least bias in the same direction. As an example of why that is true, if player A has a large bias (say 3), B had a bias of 2, and C had a bias of 1, the maximum of AB and AC is the same, but the minimum is different. And pairing A vs C before A vs B makes it more likely that everything balances out overall. We use the absolute value of the bias because the bias term is signed, so 2 more runner games is the larger bias, but is stored in the system as -2.
So then why 8? There isn’t a good reason why to be quite honest, I picked the number based on Olafson’s paper (scaled down, he had everything with large multipliers in the hundreds). Any exponential base is fine, and 8 gives you some room for going below 8 in different increments, and below 64 (82), and almost guarantees you’ll always find a suitable pairing before 83 occurs. But this could be changed to 10, 100, whatever. Part of my motivation for using the triangular number sequence (instead of any other non-linear integer sequence) was I could multiply the early numbers by small integers and still be smaller than 8.
Score Factor
So now we get to the score factor. The side bias term is always going to be discrete, 0, 8, 64, 512. The number we get out from the score cost may include fractions (due to ties), but generally will be 0, 1, 3, 6, 10, 15, 21, etc. So now if we think of players A, B, C where A and B have 1 win, and +1 side bias, and C has 3 wins and -1 side bias we could end up with different optimal pairings. By default, using the two factors I outlined above, the cost for A to pair with B would be 8, and the cost would be 3 for A to pair with C. So generally the algorithm will probably pair A against C because that’s the lower cost. But we could add a multiplier to the score factor term to change the relative weighting of the two terms.
So a score factor of 3 would mean now the cost of A vs B would remain 8, but A vs C would be 9 (3*3), so it becomes a less desirable pairing. So for a range of different score factors we get the table below. Each score cost * score factor is colored in the center of the table. The number of rows down (win difference) is what the final score cost will be. The green cells are ones where the score cost of going up/down the standings to find someone with a different bias is going to be less than playing someone with the same score and bias (So A vs C is a better pairing than A vs B). When you get to the yellow, those are showing how far the algorithm will cost A vs C less than A vs. B if A and B both had a side bias for +/- 2.
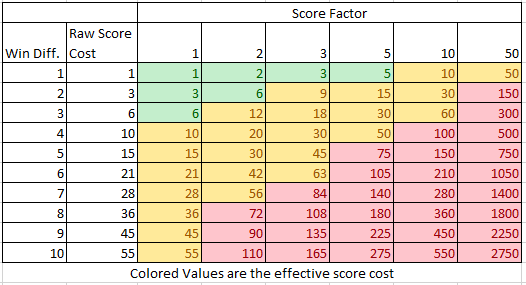
In my tests, a score factor of 2 vs 3 had a difference of 0.05 in overall pair up/downs per tournament (for a 28 person tournament), but one tenth the number of tournaments where some number of players went home with uneven sides. So for those mid-size tournaments, I’m recommending a score factor of 2. I’ll do more testing on smaller player counts 6-20, but I suspect being a bit more flexible with scores, and more rigid about sides will often end up coming out pretty fair.
A note about Re-pairing
Currently I allow re-pairing provided both players are playing the opposite side provided it does not hurt their side bias. If A has played B but not C, and both B and C have equal score factors and side biases, the algorithm is equally likely to choose either of them. This could be a behavior that people want tweaked, to avoid early (round 2 especially) rematches that can occur frequently in small tournaments (or tournaments where one side won a large predominance of games). This could be simply adding 1 to the cost if two people have played already, which would be smaller than any other contribution, so should only change the pairings in the case described above.
Conclusion
Hopefully this is a helpful summary of the nuts and bolts of the algorithm. I don’t think this should be needed to understand to run a tournament. But I figured, now that I’ve got a working app, with a somewhat opaque strategy, it would be worth sharing how it works, and some of how I got there.
I think single sided swiss solves some significant issues with the current Netrunner tournament format. Through this pairing algorithm one of the major drawbacks of single sided swiss can be mitigated to be almost a non-issue. If you’re interested in some of the theoretical data to support this solution I’ve got a whole series of articles on my blog. I built this app, and wrote this article because as a community we should be testing out single sided swiss for all event sizes. Without data I don’t think we will know how well this works or doesn’t work without testing, and I wanted to give people more tools to test this. One day hopefully this algorithm can be integrated with Cobr.ai, but until then this desktop app should hopefully be enough to get this going.
I want to thank Timmy Wong, SimonMoon, Sanjay, miek, and JayPumpkin who all looked at version of this article and gave very helpful feedback and edits. If you have got any questions, comments, I’m fairly active on Stimslack as Ysengrin.